
Data anonymization
 Research data anonymization is an essential process that ensures the protection of personal data while preserving the scientific value of the data. This process involves removing or modifying personal identifiers to prevent the identification of individuals whilst maintaining the analytical value of the data. Anonymization is particularly important in research involving sensitive data, such as medical, social, or behavioural data.
Research data anonymization is an essential process that ensures the protection of personal data while preserving the scientific value of the data. This process involves removing or modifying personal identifiers to prevent the identification of individuals whilst maintaining the analytical value of the data. Anonymization is particularly important in research involving sensitive data, such as medical, social, or behavioural data.
Effective data anonymization balances data protection requirements with research needs, ensuring that data remains useful for analysis whilst protecting the privacy of research participants. This balance has become increasingly important in today's digital age, as data volume and complexity grow, but so do the requirements regarding data protection and ethics.
In this section, you will learn about:
the basic principles of data anonymization and its importance in research;
when and what types of data require anonymization;
various anonymization methods depending on data type;
practical solutions using R and Python;
assessing anonymization quality;
best practices and documentation guidelines.
This section will help researchers understand the importance of data anonymization, choose the most appropriate methods and tools, and implement effective anonymization practices in their research, ensuring both data protection and scientific integrity.
Data anonymization is a process in which information that allows individuals to be identified is removed or modified from a dataset whilst preserving the data's analytical value. This process is essential to protect the privacy of research participants and ensure compliance with data protection regulations, especially the General Data Protection Regulation (GDPR).
Key aspects of data anonymization:
anonymization versus pseudonymization: anonymization makes data completely unrecognisable, preventing any possibility of identifying individuals. Pseudonymization replaces identifiers with pseudonyms but retains a theoretical possibility of identifying individuals if additional information is available. In the GDPR context, only fully anonymized data are no longer considered personal data;
direct and indirect identifiers: direct identifiers (names, personal identification numbers, emails) directly identify a person. Indirect identifiers (dates of birth, postcodes, occupations) can identify a person in combination with other data. Effective anonymization must address both types;
legal framework: GDPR and other data protection laws impose strict requirements for processing personal data. Anonymized data that no longer allow individuals to be identified fall outside the scope of these laws, which facilitates their use in research;
anonymization allows researchers to:
share data with the wider scientific community;
publish data in open repositories;
use data for secondary analysis without additional consent;
reduce data security risks.
limitations of anonymization: it should be noted that nowadays, with increasing data volume and diversity, complete anonymization is becoming increasingly difficult to achieve. There are significant reidentification risks, especially in cases where anonymized data are combined with other publicly available data sources.
Understanding these basic principles is essential for researchers to make informed decisions about data anonymization and choose the most appropriate methods for their research.
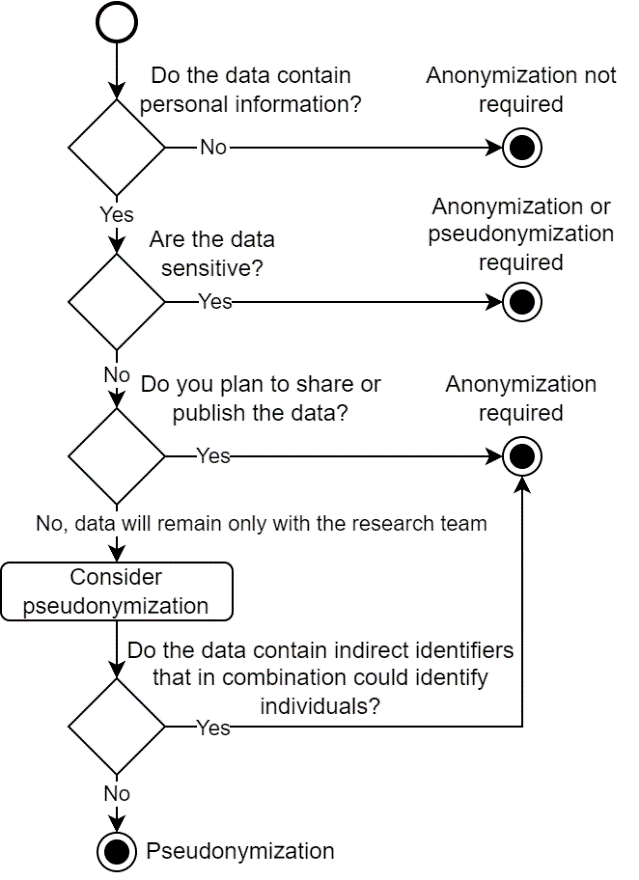
The decision on when and what data to anonymize depends on several factors, including the type of data, research purpose, and legal requirements. This section will help researchers make informed decisions about the necessity of anonymization.
Anonymization is necessary in:
personal data processing: if your research involves any information that can identify a living person (directly or indirectly), anonymization should be considered;
data sharing: if you plan to share data outside the original research team or publish it in repositories;
secondary analysis: if the data will be used for purposes not originally specified in participant consent;
long-term data preservation: if the data will be archived for long-term preservation after the end of the research.
Types of data requiring anonymization:
1. Direct identifiers (always need to be anonymized):
names, surnames; personal identification numbers, social security numbers;
contact information (telephone numbers, emails, addresses);
biometric data (fingerprints, facial images);
unique identifiers (student IDs, patient numbers).
2. Indirect identifiers (context needs to be assessed):
demographic data (gender, age, ethnicity);
geographical data (postcodes, cities, regions);
socioeconomic data (income, education, occupation);
health information (diagnoses, treatment history);
timestamps and dates (birth dates, event dates).
Risk assessment. Before performing anonymization, researchers should assess the re-identification risk, considering:
data uniqueness (how easy it is to identify individuals by unique characteristics);
data sensitivity (what harm could result from re-identification);
data usage context (who will access the data and for what purposes);
existence of other publicly available data sources that could be combined with your data.
This assessment will help choose the most appropriate anonymization method and level to balance privacy protection with the analytical value of the data.
Different types of data require different anonymization approaches. This section covers the most appropriate methods for each data type to maintain a balance between privacy protection and the scientific value of the data. Properly chosen methods allow researchers to preserve the analytical significance of the data whilst ensuring the protection of research participants’ privacy.
Numerical data:
aggregation: combining individual values into broader categories or groups. For example, using age groups (30-34 years) instead of exact age (32 years). This method is particularly useful if the dataset contains values that might be unique or rare. Aggregation reduces precision but often preserves sufficient information for statistical analysis. For example, in medical research, a patient’s exact age is often not necessary, and age groups provide sufficient information for epidemiological analysis;
perturbation (adding noise): adding small random errors to numerical values whilst preserving the overall statistical distribution. This method is particularly valuable when it is necessary to preserve the statistical properties of the data, such as mean and standard deviation. The level of perturbation should be chosen to be sufficient to prevent identification but not disrupt the analytical value of the data. For example, in a study on income, each value can be given a random deviation within +/- 5%, which does not significantly affect the overall analysis;
rounding: rounding precise values to a certain level of precision. This is a simple but effective method that reduces the possibility of identifying individuals by precise numerical values. For example, income data can be rounded to the nearest 100 or 1000 EUR, or weight to the nearest 5 kg. The level of rounding should be chosen according to the needs of the research and the sensitivity of the data. This method is particularly useful if the dataset contains extreme values that could be easily identified;
micro-aggregation: grouping similar records and replacing them with the group’s average value. This method preserves the statistical properties of the dataset whilst reducing the uniqueness of individual records. In the micro-aggregation process, data are sorted by a specific variable and divided into groups with an equal number of records (usually 3 to 5). The values of each group are replaced with the group’s average value. This method is particularly useful for multifactor datasets where multiple variables could together identify individuals.
Categorical data:
generalisation: combining detailed categories into broader groups, reducing data granularity. This method is particularly important if the categories are very specific or rare. For example, instead of a precise profession (“neurosurgeon in a specialised children’s hospital”), a more general category (“medical specialist”) can be used. The level of generalisation should be adapted to the sensitivity of the data and the needs of the research. Too broad generalisation can reduce the analytical value of the data, but insufficient generalisation can preserve the risk of re-identification;
value suppression: removing or replacing rare or unique values to prevent the possibility of identifying individuals by these unique characteristics. Replacement can be complete (the value is removed) or partial (the value is replaced with a general designation, such as “other”). This method is particularly important in small datasets or cases where certain categories are very rare. For example, if in a study on professions there is only one astronaut, this value could be replaced with “science and engineering specialist”;
recoding: replacing original categories with codes or pseudonyms that do not reflect the original meaning. This method is useful if the category names themselves contain identifying information. For example, school names can be replaced with codes (“School A”, “School B”), or ethnic groups with more general designations. Recoding is often combined with other methods, such as generalisation, to ensure more effective anonymization.
Text data (interviews, open questions):
identifier redaction: removal or replacement of direct identifiers (names, places, organisations) with markers or pseudonyms. This is a basic method for anonymizing qualitative data that allows preserving the meaning of the text whilst protecting the identity of participants. For example, in an interview text, the name “John Smith” can be replaced with “[Respondent 1]” or “J.S.”. In the redaction process, it is important to maintain consistency throughout the dataset, using a unified approach to replacing identifiers;
paraphrasing: rewriting text, preserving its meaning but changing the wording to avoid identifying language peculiarities or narrative elements. This method is particularly important if the respondent’s manner of expression or narrative details could be identifying. Paraphrasing requires a careful balance between preserving the authenticity of the text and protecting privacy. For example, if a respondent tells about a unique experience that could reveal their identity, this story can be rewritten, preserving the main idea but changing the specific details;
contextual generalisation: replacing specific information with more general information, preserving the meaningfulness of the text. For example, instead of a specific school name (“Riga State Gymnasium No. 1”), a more general designation (“prestigious secondary school”) can be used. This method is particularly useful if the context is important in the research, but not the exact details. Contextual generalisation allows preserving the richness of qualitative data whilst reducing the risk of re-identification;
use of pseudonyms: replacing real names, places, and organisations with fictional names or codes, preserving the readability and meaning of the text. Unlike simple redaction, pseudonyms allow maintaining the flow and context of the text. For example, in an interview study, all participants can be assigned pseudonyms that reflect their gender and approximate age, but not their real identity. It is important to create a list of pseudonyms and use it consistently throughout the study.
Audio and video data:
voice modification: changing voice parameters (timbre, pitch, speed) in audio recordings to prevent the possibility of identifying a person by voice. This method allows preserving the content of the audio recording whilst protecting the speaker’s identity. Voice modification is particularly important in cases where audio recordings are published or shared. Modern software allows voice modification whilst preserving speech intelligibility and emotional colouring;
face blurring or pixelation: blurring or pixelating faces and other identifying features (tattoos, characteristic scars) visible in video materials. This is a standard method for anonymizing video materials that allows preserving the context and content of the video whilst protecting the identity of individuals. Modern video processing software offers automated tools for face recognition and blurring, which facilitates this process;
use of transcripts: transcribing audio or video materials and sharing only anonymized transcripts. This method completely eliminates the possibility of identifying individuals by voice or appearance but preserves the content of conversations or events. Transcripts can be further anonymized using text anonymization methods. This approach is particularly useful if only the content of conversations is important in the research, not the paraverbal or nonverbal communication.
Geospatial data:
geographical generalisation: replacing precise coordinates or addresses with broader geographical areas. For example, instead of a precise address, a city district or postcode can be used. The level of generalisation should be adapted to the needs of the research and the sensitivity of the data. In densely populated areas, it may be sufficient to indicate the district, but in sparsely populated areas, it may be necessary to use a broader region to ensure anonymity;
coordinate perturbation: adding small random deviations to geographical coordinates, preserving the approximate location but preventing precise identification. This method is particularly useful in ecological or epidemiological studies where the spatial distribution is important, but not the exact locations. The level of perturbation should be adapted to the needs of the research – greater perturbation provides better privacy but reduces spatial precision;
aggregation by administrative units: combining individual locations by administrative units (parishes, counties, cities). This method allows preserving the spatial distribution of data at the macro level whilst preventing the possibility of identifying specific individuals or households. The level of aggregation should be chosen according to the research objectives and data sensitivity – in densely populated areas, it may be sufficient to use smaller administrative units, but in sparsely populated areas, larger units are needed.
This section covers practical solutions for data anonymization using the most popular data analysis tools – R and Python. Each tool has its advantages and limitations, and the most appropriate choice depends on the researcher's skills, data type, and anonymization requirements.
R solutions:
sdcMicro package: this is the most comprehensive R package for statistical data anonymization, offering a wide range of methods for microdata protection. sdcMicro includes functions for anonymizing categorical and numerical data, ensuring k-anonymity, and assessing disclosure risk. The package is particularly useful for anonymizing official statistics data and large research datasets. It offers both an interactive graphical interface and command-line functions that allow automating the anonymization process. For example, the localSuppression() function automatically identifies and masks values that create a high disclosure risk, while microaggregation() allows micro-aggregation of numerical variables;
anonymizer package: this package offers simpler tools for personal data anonymization, particularly suitable for text data and identifier replacement. It includes functions for recognising and anonymizing names, email addresses, telephone numbers, and other identifiers. The package is easy to use and suitable for researchers with limited programming skills. The anonymize() function automatically recognises and replaces the most common identifiers, while set_anon_patterns() allows defining custom identifier patterns;
dplyr and tidyr packages: these popular data manipulation packages can be used for various anonymization methods, such as aggregation, generalisation, and recoding. Although they are not specifically designed for anonymization, their flexible functions allow implementing many anonymization strategies. For example, the mutate() and case_when() functions can be used for age grouping or category generalisation, while group_by() and summarise() – for data aggregation.
Python solutions:
pandas library: this is the main data manipulation library in Python, offering many functions that can be used for data anonymization. Similar to R’s dplyr, pandas allows data aggregation, generalisation, and recoding. The cut() and qcut() functions are particularly useful for grouping numerical data, while replace() and map() can be used for generalising categorical data. Pandas also offers the sample() function for creating data subsets and the drop() function for removing sensitive variables;
Faker library: this library is designed for generating realistic but synthetic data, which is very useful for pseudonymization. It offers a wide range of functions for replacing various identifiers (names, addresses, telephone numbers, emails, etc.) with plausible but fake data. Faker is particularly useful when it is necessary to preserve the data structure and context whilst protecting personal identity. An important feature of Faker is the ability to use seed values to ensure consistent pseudonymization – the same value will always be replaced with the same pseudonym;
spaCy library: this natural language processing (NLP) library is very useful for text data anonymization. spaCy offers named entity recognition (NER) functionality that can automatically identify person names, organisations, locations, and other sensitive identifiers in text. After identification, these entities can be replaced with generalised designations or pseudonyms. spaCy supports several languages, including Latvian (with limitations), and can be adapted to specific domains.
Assessing anonymization quality is an essential step to ensure that the measures taken effectively protect personal data whilst preserving the analytical value of the data. This section covers methods and tools that can be used to evaluate the effectiveness of anonymization and identify potential risks.
Disclosure risk assessment is a process in which the probability that an individual can be re-identified in the anonymized dataset is quantitatively measured, using methods such as calculating k-anonymity, analysing unique combinations, and simulated re-identification attempts.
Disclosure risk assessment methods:
k-anonymity check: k-anonymity is one of the most commonly used measures of anonymization quality. It stipulates that each combination of records in a set of quasi-identifiers must have at least k identical records in the dataset. The higher the k value, the lower the disclosure risk. For example, if a dataset has 5-anonymity, then each record is indistinguishable from at least 4 other records based on quasi-identifiers;
unique combination analysis: this method identifies unique or rare quasi-identifier combinations that could create a high risk of re-identification. Researchers can use simple statistical methods to determine how often a specific combination of attributes appears in the dataset. Combinations that appear only once or a few times may indicate insufficient anonymization;
l-diversity check: this method complements k-anonymity by ensuring that each equivalence class (records with identical quasi-identifiers) has at least l different values of sensitive attributes. This helps prevent homogeneity attacks, where all records in an equivalence class contain the same sensitive value;
differential privacy analysis: this approach assesses the extent to which anonymized data provides differential privacy – a mathematically provable privacy guarantee. The level of differential privacy (ε) indicates the trade-off between privacy and data accuracy – lower ε values mean higher privacy but potentially lower data utility.
Data utility assessment is a process in which the extent to which anonymized data preserves the analytical value and statistical properties of the original data is measured by comparing statistical indicators, data distributions, and model results between the original and anonymized datasets.
Data utility assessment methods:
comparing statistical indicators: this method compares key statistical indicators (means, standard deviations, correlations) between the original and anonymized datasets. Small differences indicate good preservation of data utility. For example, if in the original dataset the mean age is 42.3 years with a standard deviation of 12.1, but in the anonymized dataset – 41.9 years with a standard deviation of 11.8, then data utility is well preserved;
model validation: this method assesses whether statistical or machine learning models created using anonymized data provide similar results to models created with the original data. For example, regression model coefficients or classification model accuracy can be compared;
information loss measurements: these measurements quantitatively assess how much information has been lost in the anonymization process. For example, changes in information entropy or the proportional loss of information (PLI) measure, which compares the variation of original and anonymized data, can be used;
comparing data distributions: this method visually or statistically compares data distributions before and after anonymization. Histograms, density functions, or cumulative distribution functions can help assess whether anonymization has significantly changed the data structure.
Practical methods and tools
R sdcMicro package risk assessment functions: this package offers several functions for assessing anonymization quality, including:
print(obj) – shows the current risk assessment;
riskStatus(obj) – provides detailed information about disclosure risk;
dRisk(obj) – calculates individual and global disclosure risk;
dUtility(obj) – assesses information loss.
Python ARX library risk analysis: the ARX library in Python offers comprehensive tools for assessing anonymization quality.
Trade-off between privacy and utility in assessing anonymization quality, it is important to find a balance between privacy protection and data utility. Higher privacy protection usually means greater information loss and potentially lower data utility. This trade-off can be visualised using privacy-utility diagrams that show the impact of various anonymization methods and parameters.
The choice of optimal anonymization strategy depends on the specific research context, data sensitivity, and intended use. Researchers need to determine an acceptable level of disclosure risk, considering the potential harm to individuals in case of re-identification, and choose anonymization methods that provide sufficient privacy protection whilst preserving the necessary analytical value of the data.
Regular assessment of anonymization quality is essential, as new data, methods, or external information can change the disclosure risk over time. Therefore, it is recommended to periodically review and update anonymization strategies to ensure long-term privacy protection.
Effective data anonymization requires not only the application of technical methods but also a systematic approach and careful documentation. This section covers best practices and guidelines that will help ensure quality and reliable data anonymization in research projects.
Anonymization planning and preparation:
defining anonymization objectives: before starting the anonymization process, it is important to clearly define why the data are being anonymized and how they will be used after anonymization. This understanding will help choose the most appropriate methods and assess the necessary level of anonymization. For example, if the data will be published in open access, a higher level of anonymization will be needed than if they will be shared only with trusted researchers in a controlled environment;
data inventory: before performing anonymization, a thorough data inventory should be conducted, identifying all direct identifiers, quasi-identifiers, and sensitive attributes. At this stage, it is important to involve domain experts who can help identify indirect identifiers that may not be obvious. For example, in medical research, rare diseases or specific treatment methods can serve as indirect identifiers;
risk assessment: before choosing anonymization methods, an initial re-identification risk assessment should be conducted, considering the data context, potential “attackers”, and available external information. This assessment will help determine what level of anonymization is needed and which methods would be most appropriate. For example, if the research is conducted in a small community or specific professional group, the re-identification risk may be higher;
awareness of legal requirements: before anonymization, one should become familiar with the relevant data protection laws and regulations (e.g., GDPR in the European Union) and ensure that the anonymization process complies with these requirements. This may include consultations with data protection specialists or legal experts;
inclusion of ethical considerations: anonymization planning should take into account not only legal but also ethical aspects, including potential harm to individuals in case of re-identification and the rights and interests of data subjects. This is particularly important for sensitive data, such as health or financial information.
Documenting the anonymization process:
methodology documentation: document in detail all anonymization methods used, their parameters, and the rationale for choosing these methods. This documentation is essential both for research transparency and to ensure that other researchers can understand and evaluate the quality of anonymization. For example, if k-anonymity is used, document the chosen k value and the rationale for this choice;
code and script preservation: preserve all codes, scripts, or tools used in the anonymization process, along with comments and instructions for their use. This will help ensure the reproducibility of the anonymization process and allow it to be reviewed or modified if necessary;
keeping a change log: document all changes made to the dataset during the anonymization process, including removed or modified attributes and their original values (in a general form). This information can be useful when assessing the impact of anonymization on data analysis;
documenting risk assessment results: preserve the results of all risk assessments conducted, including identified risks, their assessment, and measures taken to mitigate risks. This documentation is essential to justify the adequacy and compliance of the anonymization process;
documenting data utility assessment: document how anonymization has affected data utility, including changes in key statistical indicators and data distributions. This information will help other researchers understand the impact of anonymization on data analysis results.
Management of anonymized data:
version control: by implementing version control for anonymized data, ensure that different anonymization versions and changes over time can be tracked. This is particularly important if the anonymization process is modified or improved based on new risks or methods;
access control: by implementing appropriate access control mechanisms for anonymized data, ensure that only authorised users can access them and that the data are used only for intended purposes. Even if the data are anonymized, access control is good practice;
defining data usage conditions: clearly define how anonymized data may be used, shared, or published, and ensure that these conditions are communicated to all data users. This may include a prohibition on attempting to re-identify individuals or combining data with other sources that could compromise anonymity;
regular risk review: periodically review the effectiveness of anonymization, taking into account new data, methods, or external information that could increase the risk of re-identification. Anonymization is not a one-time process but a continuous activity that needs to be adapted to the changing environment;
incident management plan: develop a plan for action in case a re-identification possibility is discovered or a data protection incident occurs. This plan may include procedures for assessing the incident, informing the parties involved, and taking corrective actions.
Communication and training:
clear communication with data subjects: ensure that data subjects (research participants) are properly informed about how their data will be anonymized and used. This is an essential aspect of the informed consent process and helps build trust between researchers and participants;
researcher training: ensure that all researchers working with sensitive data are trained in the principles, methods, and best practices of data anonymization. This training may include practical exercises and case studies to develop practical skills;
collaboration with data protection specialists: establish collaboration with data protection specialists or ethics committees to ensure that the anonymization process complies with all legal and ethical requirements. This collaboration can provide valuable knowledge and perspectives that can improve the quality of anonymization;
openness about limitations: be open about the limitations of anonymization and residual risks when communicating about anonymized data. This transparency helps create realistic expectations and promotes trust in the research process;
knowledge sharing: share your knowledge and experience in data anonymization with the wider research community by participating in conferences, publishing articles, or developing open-source tools. This knowledge sharing promotes the development and improvement of better practices across the industry.
By following these best practices and documentation guidelines, researchers can ensure that their data anonymization process is systematic, transparent, and effective, whilst complying with legal and ethical requirements. This not only protects the privacy of research participants but also promotes trust in the research process and results.
Abu Attieh H., Müller A., Wirth F. N., Prasser F. (2025). Pseudonymization tools for medical research: a systematic review. BMC Medical Informatics and Decision Making, 25 (1), pp. 1–10. DOI: 10.1186/s12911-025-02958-0
Carvalho T., Moniz N., Faria P., Antunes L. (2023). Survey on Privacy-Preserving Techniques for Microdata Publication. ACM Computing Surveys, 55 (14 S), pp. 1–42. DOI: 10.1145/3588765
Sepas A., Bangash A. H., Alraoui O., El Emam K., El-Hussuna A. (2022). Algorithms to anonymize structured medical and healthcare data: A systematic review. Frontiers in Bioinformatics, 2, pp. 1–11. DOI: 10.3389/fbinf.2022.984807
Stinar F., Xiong Z., Bosch N. (2024). An Approach to Improve k-Anonymization Practices in Educational Data Mining. Journal of Educational Data Mining, 16 (1), pp. 61–83. DOI: 10.5281/zenodo.11056083
Tomás J., Rasteiro D., Bernardino J. (2022). Data Anonymization: An Experimental Evaluation Using Open-Source Tools. Future Internet, 14 (6), pp. 1–20. DOI: 10.3390/fi14060167