
Datu anonimizācija
 Pētniecības datu anonimizācija ir būtisks process, kas nodrošina personas datu aizsardzību, vienlaikus saglabājot datu zinātnisko vērtību. Šis process ietver personas identifikatoru noņemšanu vai modificēšanu, lai novērstu indivīdu identificēšanas iespējas, vienlaikus saglabājot datu analītisko vērtību. Anonimizācija ir īpaši svarīga pētījumos, kas ietver sensitīvus datus, piemēram, medicīniskos, sociālos vai uzvedības datus.
Pētniecības datu anonimizācija ir būtisks process, kas nodrošina personas datu aizsardzību, vienlaikus saglabājot datu zinātnisko vērtību. Šis process ietver personas identifikatoru noņemšanu vai modificēšanu, lai novērstu indivīdu identificēšanas iespējas, vienlaikus saglabājot datu analītisko vērtību. Anonimizācija ir īpaši svarīga pētījumos, kas ietver sensitīvus datus, piemēram, medicīniskos, sociālos vai uzvedības datus.
Efektīva datu anonimizācija līdzsvaro datu aizsardzības prasības ar pētniecības vajadzībām, nodrošinot, ka dati joprojām ir noderīgi analīzei, vienlaikus aizsargājot pētījuma dalībnieku privātumu. Šis līdzsvars ir kļuvis arvien svarīgāks mūsdienu digitālajā laikmetā, kad datu apjoms un sarežģītība pieaug, bet arī palielinās prasības attiecībā uz datu aizsardzību un ētiku.
Šajā sadaļā jūs uzzināsiet par:
datu anonimizācijas pamatprincipiem un tās nozīmi pētniecībā;
to, kad un kādiem datiem nepieciešama anonimizācija;
dažādām anonimizācijas metodēm atkarībā no datu veida;
praktiskiem risinājumiem, izmantojot R un Python;
anonimizācijas kvalitātes novērtēšanu;
labajām praksēm un dokumentācijas vadlīnijām.
Šī sadaļa palīdzēs pētniekiem izprast datu anonimizācijas nozīmi, izvēlēties piemērotākās metodes un rīkus, kā arī ieviest efektīvas anonimizācijas prakses savos pētījumos, nodrošinot gan datu aizsardzību, gan zinātnisko integritāti.
Datu anonimizācija ir process, kurā no datu kopas tiek noņemta vai modificēta informācija, kas ļauj identificēt indivīdus, vienlaikus saglabājot datu analītisko vērtību. Šis process ir būtisks, lai aizsargātu pētījuma dalībnieku privātumu un nodrošinātu atbilstību datu aizsardzības regulējumam, īpaši Vispārīgajai datu aizsardzības regulai (VDAR).
Galvenie datu anonimizācijas aspekti:
anonimizācija pret pseidonimizāciju: anonimizācija padara datus pilnībā neatpazīstamus, novēršot jebkādu iespēju identificēt indivīdus. Pseidonimizācija aizstāj identifikatorus ar pseidonīmiem, bet saglabā teorētisku iespēju identificēt indivīdus, ja ir pieejama papildu informācija. VDAR kontekstā tikai pilnībā anonimizēti dati vairs netiek uzskatīti par personas datiem;
tiešie un netiešie identifikatori: tiešie identifikatori (vārdi, personas kodi, e-pasti) tieši identificē personu. Netiešie identifikatori (dzimšanas datumi, pasta indeksi, profesijas) var identificēt personu kombinācijā ar citiem datiem. Efektīvai anonimizācijai jāpievērš uzmanība abiem veidiem;
tiesiskais regulējums: VDAR un citi datu aizsardzības likumi nosaka stingras prasības personas datu apstrādei. Anonimizēti dati, kas vairs neļauj identificēt indivīdus, neietilpst šo likumu darbības jomā, kas atvieglo to izmantošanu pētniecībā;
anonimizācija ļauj pētniekiem:
dalīties ar datiem plašākā zinātniskajā kopienā;
publicēt datus atvērtajos repozitorijos;
izmantot datus sekundārai analīzei bez papildu piekrišanas;
samazināt datu drošības riskus;
anonimizācijas ierobežojumi: jāņem vērā, ka mūsdienās, pieaugot datu apjomam un daudzveidībai, pilnīga anonimizācija kļūst aizvien grūtāk sasniedzama. Pastāv nozīmīgi reidentifikācijas riski, īpaši gadījumos, kad anonimizēti dati tiek kombinēti ar citiem publiski pieejamiem datu avotiem.
Izpratne par šiem pamatprincipiem ir būtiska, lai pētnieki varētu pieņemt informētus lēmumus par datu anonimizāciju un izvēlēties piemērotākās metodes saviem pētījumiem.
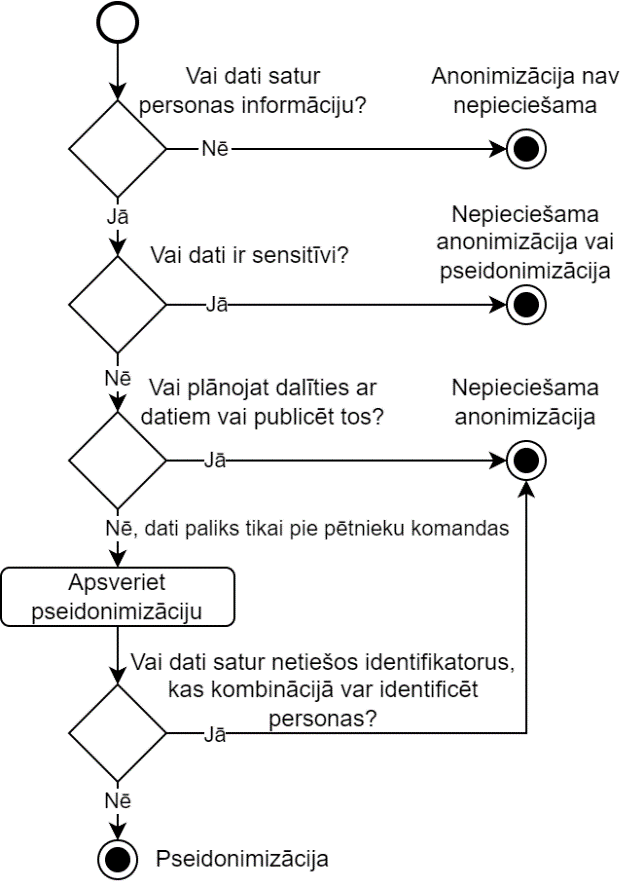
Lēmums par to, kad un kādus datus anonimizēt, ir atkarīgs no vairākiem faktoriem, t.sk. datu veida, pētījuma mērķa un tiesiskajām prasībām. Šī sadaļa palīdzēs pētniekiem pieņemt informētus lēmumus par anonimizācijas nepieciešamību.
Anonimizācija nepieciešama:
personas datu apstrādē: ja jūsu pētījums ietver jebkādu informāciju, kas var identificēt dzīvu personu (tieši vai netieši), jāapsver anonimizācija;
datu koplietošanā: ja plānojat dalīties ar datiem ārpus sākotnējās pētnieku komandas vai publicēt tos repozitorijos;
sekundārajā analīzē: ja dati tiks izmantoti mērķiem, kas nav sākotnēji norādīti dalībnieku piekrišanā;
ilgtermiņa datu saglabāšanā: ja dati tiks arhivēti ilgtermiņa saglabāšanai pēc pētījuma beigām.
Datu veidi, kam nepieciešama anonimizācija:
1. Tiešie identifikatori (vienmēr jāanonimizē):
vārdi, uzvārdi;
personas kodi, sociālās apdrošināšanas numuri;
kontaktinformācija (tālruņa numuri, e-pasti, adreses);
biometriskie dati (pirkstu nospiedumi, sejas attēli);
unikālie identifikatori (studentu ID, pacienta numuri).
2. Netiešie identifikatori (jānovērtē konteksts):
demogrāfiskie dati (dzimums, vecums, etniskā piederība);
ģeogrāfiskie dati (pasta indeksi, pilsētas, reģioni);
sociālekonomiskie dati (ienākumi, izglītība, profesija);
veselības informācija (diagnozes, ārstēšanas vēsture);
laika zīmogi un datumi (dzimšanas datumi, notikumu datumi).
Riska novērtējums. Pirms anonimizācijas veikšanas, pētniekiem jānovērtē re-identifikācijas risks, ņemot vērā:
datu unikalitāti (cik viegli identificēt indivīdus pēc unikālām iezīmēm);
datu jutīgumu (kāds kaitējums varētu rasties re-identifikācijas gadījumā);
datu izmantošanas kontekstu (kas piekļūs datiem un kādiem mērķiem);
citu publiski pieejamu datu avotu esamību, kas varētu tikt kombinēti ar jūsu datiem.
Šis novērtējums palīdzēs izvēlēties piemērotāko anonimizācijas metodi un līmeni, lai sabalansētu privātuma aizsardzību ar datu analītisko vērtību.
Dažādiem datu veidiem nepieciešamas atšķirīgas anonimizācijas pieejas. Šajā sadaļā aplūkotas piemērotākās metodes katram datu veidam, lai saglabātu līdzsvaru starp privātuma aizsardzību un datu zinātnisko vērtību. Pareizi izvēlētas metodes ļauj pētniekiem saglabāt datu analītisko nozīmi, vienlaikus nodrošinot pētījuma dalībnieku privātuma aizsardzību.
Skaitliskie dati:
agregācija: individuālo vērtību apvienošana plašākās kategorijās vai grupās. Piemēram, precīza vecuma (32 gadi) vietā izmantojot vecuma grupas (30-34 gadi). Šī metode ir īpaši noderīga, ja datu kopā ir vērtības, kas varētu būt unikālas vai reti sastopamas. Agregācija samazina precizitāti, bet bieži saglabā pietiekamu informāciju statistiskajai analīzei. Piemēram, medicīniskajos pētījumos pacienta precīzs vecums bieži nav nepieciešams, un vecuma grupas nodrošina pietiekamu informāciju epidemioloģiskajai analīzei;
perturbācija (trokšņa pievienošana): nelielu gadījuma kļūdu pievienošana skaitliskajām vērtībām, saglabājot kopējo statistisko sadalījumu. Šī metode ir īpaši vērtīga, kad nepieciešams saglabāt datu statistiskās īpašības, piemēram, vidējo vērtību un standartnovirzi. Perturbācijas līmenis jāizvēlas tā, lai tas būtu pietiekams identifikācijas novēršanai, bet neizjauktu datu analītisko vērtību. Piemēram, pētījumā par ienākumiem katrai vērtībai var pievienot nejaušu novirzi +/- 5% robežās, kas būtiski neietekmē kopējo analīzi;
noapaļošana: precīzu vērtību noapaļošana līdz noteiktam precizitātes līmenim. Šī ir vienkārša, bet efektīva metode, kas samazina iespēju identificēt personas pēc precīzām skaitliskām vērtībām. Piemēram, ienākumu datus var noapaļot līdz tuvākajiem 100 vai 1000 EUR, vai svaru līdz tuvākajiem 5 kg. Noapaļošanas līmenis jāizvēlas atbilstoši pētījuma vajadzībām un datu jutīgumam. Šī metode ir īpaši noderīga, ja datu kopā ir ekstremālas vērtības, kas varētu būt viegli identificējamas;
mikro-agregācija: līdzīgu ierakstu grupēšana un aizstāšana ar grupas vidējo vērtību. Šī metode saglabā datu kopas statistiskās īpašības, vienlaikus samazinot individuālo ierakstu unikalitāti. Mikro-agregācijas procesā dati tiek sakārtoti pēc noteikta mainīgā un sadalīti grupās ar vienādu ierakstu skaitu (parasti 3 līdz 5). Katras grupas vērtības tiek aizstātas ar grupas vidējo vērtību. Šī metode ir īpaši noderīga daudzfaktoru datu kopām, kur vairāki mainīgie varētu kopā identificēt personas.
Kategoriskie dati:
vispārināšana: detalizētu kategoriju apvienošana plašākās grupās, samazinot datu granularitāti. Šī metode ir īpaši svarīga, ja kategorijas ir ļoti specifiskas vai reti sastopamas. Piemēram, precīzas profesijas (“neiroķirurgs specializētā bērnu slimnīcā”) vietā var izmantot vispārīgāku kategoriju (“medicīnas speciālists”). Vispārināšanas līmenis jāpielāgo datu jutīgumam un pētījuma vajadzībām. Pārāk plaša vispārināšana var samazināt datu analītisko vērtību, bet nepietiekama vispārināšana var saglabāt re-identifikācijas risku;
vērtību aizstāšana: retu vai unikālu vērtību noņemšana vai aizstāšana, lai novērstu iespēju identificēt personas pēc šīm unikālajām iezīmēm. Aizstāšana var būt pilnīga (vērtība tiek izņemta) vai daļēja (vērtība tiek aizstāta ar vispārīgu apzīmējumu, piemēram, “cits”). Šī metode ir īpaši svarīga mazās datu kopās vai gadījumos, kad noteiktas kategorijas ir ļoti reti sastopamas. Piemēram, ja pētījumā par profesijām ir tikai viens astronauts, šī vērtība varētu tikt aizstāta ar “zinātnes un inženierijas speciālists”;
pārkodēšana: oriģinālo kategoriju aizstāšana ar kodiem vai pseidonīmiem, kas neatspoguļo sākotnējo nozīmi. Šī metode ir noderīga, ja kategoriju nosaukumi paši par sevi satur identificējošu informāciju. Piemēram, skolu nosaukumi var tikt aizstāti ar kodiem (“Skola A”, “Skola B”), vai etniskās grupas ar vispārīgākiem apzīmējumiem. Pārkodēšana bieži tiek kombinēta ar citām metodēm, piemēram, vispārināšanu, lai nodrošinātu efektīvāku anonimizāciju.
Teksta dati (intervijas, atvērtie jautājumi):
identifikatoru redakcija: tiešo identifikatoru (vārdi, vietas, organizācijas) izņemšana vai aizstāšana ar marķieriem vai pseidonīmiem. Šī ir pamata metode kvalitatīvo datu anonimizācijai, kas ļauj saglabāt teksta jēgu, vienlaikus aizsargājot dalībnieku identitāti. Piemēram, intervijas tekstā vārds “Jānis Bērziņš” var tikt aizstāts ar “[Respondents 1]” vai “J.B.”. Redakcijas procesā svarīgi saglabāt konsekvenci visā datu kopā, izmantojot vienotu pieeju identifikatoru aizstāšanai;
parafrāzēšana: teksta pārrakstīšana, saglabājot tā nozīmi, bet mainot formulējumu, lai novērstu identificējošas valodas īpatnības vai stāstījuma elementus. Šī metode ir īpaši svarīga, ja respondenta izteikšanās veids vai stāstījuma detaļas varētu būt identificējošas. Parafrāzēšana prasa rūpīgu līdzsvaru starp teksta autentiskuma saglabāšanu un privātuma aizsardzību. Piemēram, ja respondents stāsta par unikālu pieredzi, kas varētu atklāt viņa identitāti, šis stāsts var tikt pārrakstīts, saglabājot galveno domu, bet mainot specifiskās detaļas;
kontekstuālā vispārināšana: specifiskas informācijas aizstāšana ar vispārīgāku, saglabājot teksta jēgpilnumu. Piemēram, konkrētas skolas nosaukuma (“Rīgas Valsts 1. ģimnāzija”) vietā var izmantot vispārīgāku apzīmējumu (“prestiža vidusskola”). Šī metode ir īpaši noderīga, ja pētījumā svarīgs ir konteksts, bet ne precīzas detaļas. Kontekstuālā vispārināšana ļauj saglabāt kvalitatīvo datu bagātību, vienlaikus samazinot reidentifikācijas risku;
pseidonīmu izmantošana: reālu vārdu, vietu un organizāciju aizstāšana ar izdomātiem nosaukumiem vai kodiem, saglabājot teksta lasāmību un jēgu. Atšķirībā no vienkāršas redakcijas pseidonīmi ļauj saglabāt teksta plūdumu un kontekstu. Piemēram, interviju pētījumā visiem dalībniekiem var piešķirt pseidonīmus, kas atspoguļo viņu dzimumu un aptuveno vecumu, bet ne reālo identitāti. Svarīgi izveidot pseidonīmu sarakstu un konsekventi to izmantot visā pētījumā.
Audio un videodati:
balss modificēšana: balss parametru (tembra, augstuma, ātruma) mainīšana audioierakstos, lai novērstu iespēju identificēt personu pēc balss. Šī metode ļauj saglabāt audioieraksta saturu, vienlaikus aizsargājot runātāja identitāti. Balss modificēšana ir īpaši svarīga gadījumos, kad audioieraksti tiek publicēti vai koplietoti. Mūsdienu programmatūra ļauj veikt balss modificēšanu, saglabājot runas saprotamību un emocionālo nokrāsu;
seju aizmiglošana vai pikselizācija: videomateriālos redzamo seju un citu identificējošu iezīmju (tetovējumu, raksturīgu rētu) aizmiglošana vai pikselizācija. Šī ir standarta metode videomateriālu anonimizācijai, kas ļauj saglabāt video kontekstu un saturu, vienlaikus aizsargājot personu identitāti. Mūsdienu video apstrādes programmatūra piedāvā automatizētus rīkus seju atpazīšanai un aizmiglošanai, kas atvieglo šo procesu;
transkriptu izmantošana: audio vai videomateriālu transkribēšana un tikai anonimizētu transkriptu koplietošana. Šī metode pilnībā novērš iespēju identificēt personas pēc balss vai izskata, bet saglabā sarunu vai notikumu saturu. Transkripti var tikt papildus anonimizēti, izmantojot teksta anonimizācijas metodes. Šī pieeja ir īpaši noderīga, ja pētījumā svarīgs ir tikai sarunu saturs, nevis paraverbālā vai neverbālā komunikācija.
Ģeotelpiskie dati:
ģeogrāfiskā vispārināšana: precīzu koordinātu vai adrešu aizstāšana ar plašākiem ģeogrāfiskiem apgabaliem. Piemēram, precīzas adreses vietā var izmantot pilsētas rajonu vai pasta indeksu. Vispārināšanas līmenis jāpielāgo pētījuma vajadzībām un datu jutīgumam. Blīvi apdzīvotās teritorijās var būt pietiekami norādīt rajonu, bet mazapdzīvotās teritorijās var būt nepieciešams izmantot plašāku reģionu, lai nodrošinātu anonimitāti;
koordinātu perturbācija: nelielu gadījuma noviržu pievienošana ģeogrāfiskajām koordinātām, saglabājot aptuveno atrašanās vietu, bet novēršot precīzu identifikāciju. Šī metode ir īpaši noderīga ekoloģiskajos vai epidemioloģiskajos pētījumos, kur svarīgs ir telpiskais sadalījums, bet ne precīzas lokācijas. Perturbācijas līmenis jāpielāgo pētījuma vajadzībām – lielāka perturbācija nodrošina labāku privātumu, bet samazina telpisko precizitāti;
agregācija pēc administratīvajām vienībām: individuālo lokāciju apvienošana pēc administratīvajām vienībām (pagasti, novadi, pilsētas). Šī metode ļauj saglabāt datu telpisko sadalījumu makrolīmenī, vienlaikus novēršot iespēju identificēt konkrētas personas vai mājsaimniecības. Agregācijas līmenis jāizvēlas atbilstoši pētījuma mērķiem un datu jutīgumam – blīvi apdzīvotās teritorijās var būt pietiekami izmantot mazākas administratīvās vienības, bet mazapdzīvotās teritorijās nepieciešamas lielākas vienības.
Šajā sadaļā aplūkoti praktiskie risinājumi datu anonimizācijai, izmantojot populārākos datu analīzes rīkus – R un Python. Katram rīkam ir savas priekšrocības un ierobežojumi, un piemērotākā izvēle ir atkarīga no pētnieka prasmēm, datu veida un anonimizācijas prasībām.
R risinājumi:
sdcMicro pakotne: šī ir visaptverošākā R pakotne statistisko datu anonimizācijai, kas piedāvā plašu metožu klāstu mikrodatu aizsardzībai. sdcMicro ietver funkcijas kategorisko un skaitlisko datu anonimizācijai, k-anonimitātes nodrošināšanai un atklāšanas riska novērtēšanai. Pakotne ir īpaši noderīga oficiālās statistikas datu un lielu pētījumu datu kopu anonimizācijai. Tā piedāvā gan interaktīvu grafisko saskarni, gan komandrindu funkcijas, kas ļauj automatizēt anonimizācijas procesu. Piemēram, funkcija localSuppression() automātiski identificē un nomaskē vērtības, kas rada augstu atklāšanas risku, bet microaggregation() ļauj veikt mikro-agregāciju skaitliskiem mainīgajiem;
anonymizer pakotne: šī pakotne piedāvā vienkāršākus rīkus personas datu anonimizācijai, īpaši piemērota teksta datiem un identifikatoru aizstāšanai. Tā ietver funkcijas vārdu, e-pasta adrešu, tālruņa numuru un citu identifikatoru atpazīšanai un anonimizācijai. Pakotne ir viegli lietojama un piemērota pētniekiem ar ierobežotām programmēšanas prasmēm. Funkcija anonymize() automātiski atpazīst un aizstāj biežāk sastopamos identifikatorus, bet set_anon_patterns() ļauj definēt pielāgotus identifikatoru modeļus;
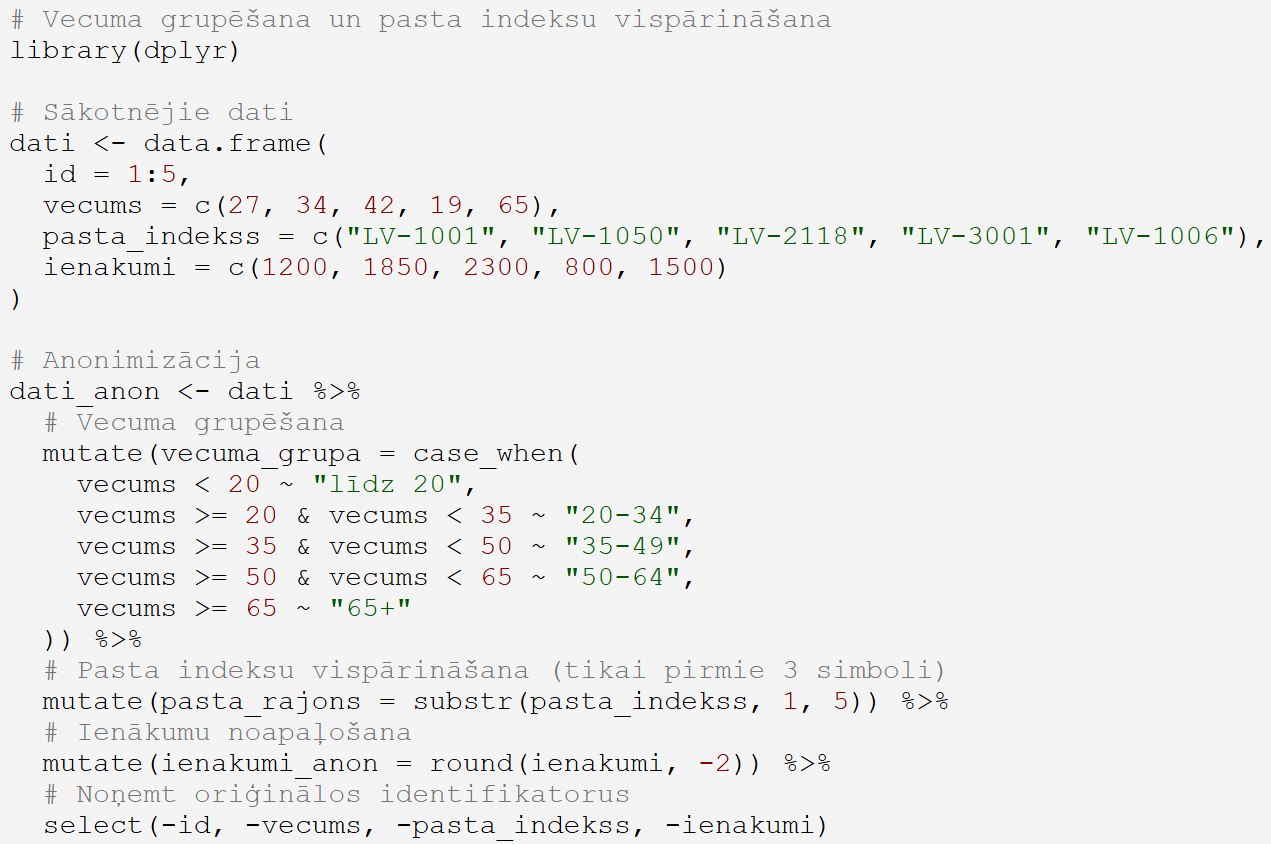
dplyr un tidyr pakotnes: šīs populārās datu manipulācijas pakotnes var izmantot dažādām anonimizācijas metodēm, piemēram, agregācijai, vispārināšanai un pārkodēšanai. Lai gan tās nav specifiski paredzētas anonimizācijai, to elastīgās funkcijas ļauj īstenot daudzas anonimizācijas stratēģijas. Piemēram, mutate() un case_when() funkcijas var izmantot vecuma grupēšanai vai kategoriju vispārināšanai, bet group_by() un summarise() – datu agregācijai.
Piemērs R valodā:
Python risinājumi:
pandas bibliotēka: šī ir galvenā datu manipulācijas bibliotēka Python valodā, kas piedāvā daudzas funkcijas, kas var tikt izmantotas datu anonimizācijai. Līdzīgi kā R valodas dplyr, pandas ļauj veikt datu agregāciju, vispārināšanu un pārkodēšanu. Funkcijas cut() un qcut() ir īpaši noderīgas skaitlisko datu grupēšanai, savukārt replace() un map() var izmantot kategorisko datu vispārināšanai. Pandas arī piedāvā sample() funkciju datu apakškopu veidošanai un drop() funkciju sensitīvu mainīgo izņemšanai;
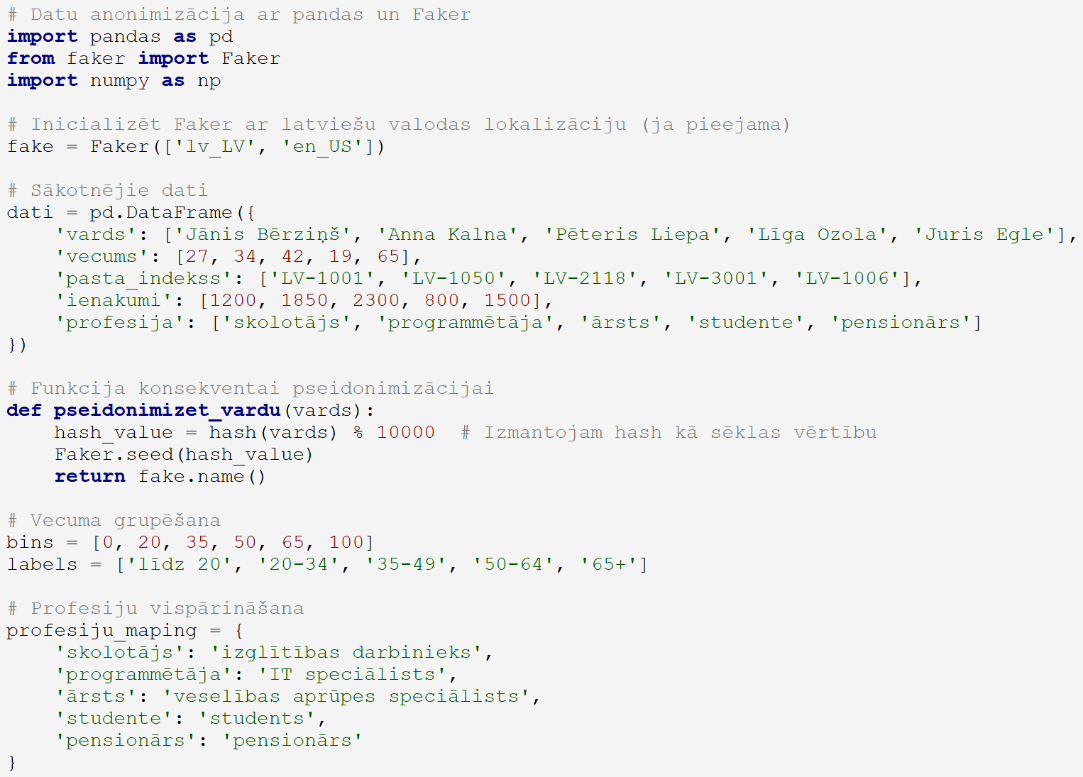
Faker bibliotēka: šī bibliotēka ir paredzēta reālistisku, bet sintētisku datu ģenerēšanai, kas ir ļoti noderīga pseidonimizācijai. Tā piedāvā plašu funkciju klāstu dažādu identifikatoru (vārdi, adreses, tālruņa numuri, e-pasti u.c.) aizstāšanai ar ticamiem, bet neīstiem datiem. Faker ir īpaši noderīgs, kad nepieciešams saglabāt datu struktūru un kontekstu, vienlaikus aizsargājot personas identitāti. Svarīga Faker īpašība ir iespēja izmantot sēklas vērtības (seed), lai nodrošinātu konsekventu pseidonimizāciju – viena un tā pati vērtība vienmēr tiks aizstāta ar vienu un to pašu pseidonīmu;
spaCy bibliotēka: šī dabiskās valodas apstrādes (NLP) bibliotēka ir ļoti noderīga teksta datu anonimizācijai. spaCy piedāvā nosaukto entītiju atpazīšanas (NER) funkcionalitāti, kas var automātiski identificēt personas vārdus, organizācijas, lokācijas un citus sensitīvus identifikatorus tekstā. Pēc identifikācijas šīs entītijas var aizstāt ar vispārinātiem apzīmējumiem vai pseidonīmiem. spaCy atbalsta vairākas valodas, t.sk. latviešu valodu (ar ierobežojumiem), un var tikt pielāgota specifiskiem domēniem.
Piemērs Python valodā:

Anonimizācijas kvalitātes novērtēšana ir būtisks solis, lai pārliecinātos, ka veiktie pasākumi efektīvi aizsargā personas datus, vienlaikus saglabājot datu analītisko vērtību. Šajā sadaļā aplūkotas metodes un rīki, ar kuriem var novērtēt anonimizācijas efektivitāti un identificēt potenciālos riskus.
Atklāšanas riska novērtēšana ir process, kurā tiek kvantitatīvi izmērīta varbūtība, ka indivīdu var reidentificēt anonimizētajā datu kopā, izmantojot tādas metodes kā k-anonimitātes aprēķināšana, unikālo kombināciju analīze un simulēti reidentifikācijas mēģinājumi.
Atklāšanas riska novērtēšanas metodes:
k-anonimitātes pārbaude: k-anonimitāte ir viens no visbiežāk izmantotajiem anonimizācijas kvalitātes mēriem. Tā nosaka, ka katrai ierakstu kombinācijai kvazi-identifikatoru kopā jābūt vismaz k identiskiem ierakstiem datu kopā. Jo lielāka k vērtība, jo zemāks atklāšanas risks. Piemēram, ja datu kopā ir 5-anonimitāte, tad katrs ieraksts ir neatšķirams no vismaz 4 citiem ierakstiem, pamatojoties uz kvazi-identifikatoriem;
unikālo kombināciju analīze: šī metode identificē unikālas vai retas kvazi-identifikatoru kombinācijas, kas varētu radīt augstu reidentifikācijas risku. Pētnieki var izmantot vienkāršas statistiskās metodes, lai noteiktu, cik bieži konkrēta atribūtu kombinācija parādās datu kopā. Kombinācijas, kas parādās tikai vienu vai dažas reizes, var norādīt uz nepietiekamu anonimizāciju;
l-daudzveidības pārbaude: šī metode papildina k-anonimitāti, nodrošinot, ka katrā ekvivalences klasē (ieraksti ar identiskiem kvazi-identifikatoriem) ir vismaz l dažādas sensitīvo atribūtu vērtības. Tas palīdz novērst homogenitātes uzbrukumus, kad visi ieraksti ekvivalences klasē satur vienu un to pašu sensitīvo vērtību;
diferenciālās privātuma analīze: šī pieeja novērtē, cik lielā mērā anonimizētie dati nodrošina diferenciālo privātumu – matemātiski pierādāmu privātuma garantiju. Diferenciālā privātuma līmenis (ε) norāda uz kompromisu starp privātumu un datu precizitāti – zemākas ε vērtības nozīmē augstāku privātumu, bet potenciāli zemāku datu lietderību.
Datu lietderības novērtēšana ir process, kurā tiek mērīts, cik lielā mērā anonimizētie dati saglabā oriģinālo datu analītisko vērtību un statistiskās īpašības, salīdzinot statistiskos rādītājus, datu sadalījumus un modeļu rezultātus starp oriģinālo un anonimizēto datu kopu.
Datu lietderības novērtēšanas metodes:
statistisko rādītāju salīdzināšana: šī metode salīdzina galvenos statistiskos rādītājus (vidējās vērtības, standartnovirzes, korelācijas) starp oriģinālo un anonimizēto datu kopu. Nelielas atšķirības liecina par labu datu lietderības saglabāšanu. Piemēram, ja oriģinālajā datu kopā vecuma vidējā vērtība ir 42.3 gadi ar standartnovirzi 12.1, bet anonimizētajā datu kopā – 41.9 gadi ar standartnovirzi 11.8, tad datu lietderība ir labi saglabāta;
modeļu validācija: šī metode novērtē, vai statistiskie vai mašīnmācīšanās modeļi, kas izveidoti, izmantojot anonimizētos datus, sniedz līdzīgus rezultātus kā modeļi, kas izveidoti ar oriģinālajiem datiem. Piemēram, var salīdzināt regresijas modeļu koeficientus vai klasifikācijas modeļu precizitāti;
informācijas zuduma mērījumi: šie mērījumi kvantitatīvi novērtē, cik daudz informācijas ir zaudēts anonimizācijas procesā. Piemēram, var izmantot informācijas entropijas izmaiņas vai proporcional loss of information (PLI) mēru, kas salīdzina oriģinālo un anonimizēto datu variāciju;
datu sadalījumu salīdzināšana: šī metode vizuāli vai statistiski salīdzina datu sadalījumus pirms un pēc anonimizācijas. Histogrammas, blīvuma funkcijas vai kumulatīvās sadalījuma funkcijas var palīdzēt novērtēt, vai anonimizācija ir būtiski izmainījusi datu struktūru.
Praktiskas metodes un rīki
R sdcMicro pakotnes riska novērtēšanas funkcijas: šī pakotne piedāvā vairākas funkcijas anonimizācijas kvalitātes novērtēšanai, t.sk.:
print(obj) – parāda pašreizējo riska novērtējumu;
riskStatus(obj) – sniedz detalizētu informāciju par atklāšanas risku;
dRisk(obj) – aprēķina individuālo un globālo atklāšanas risku;
dUtility(obj) – novērtē informācijas zudumu.

Python ARX bibliotēkas risku analīze: ARX bibliotēka Python valodā piedāvā visaptverošus rīkus anonimizācijas kvalitātes novērtēšanai.
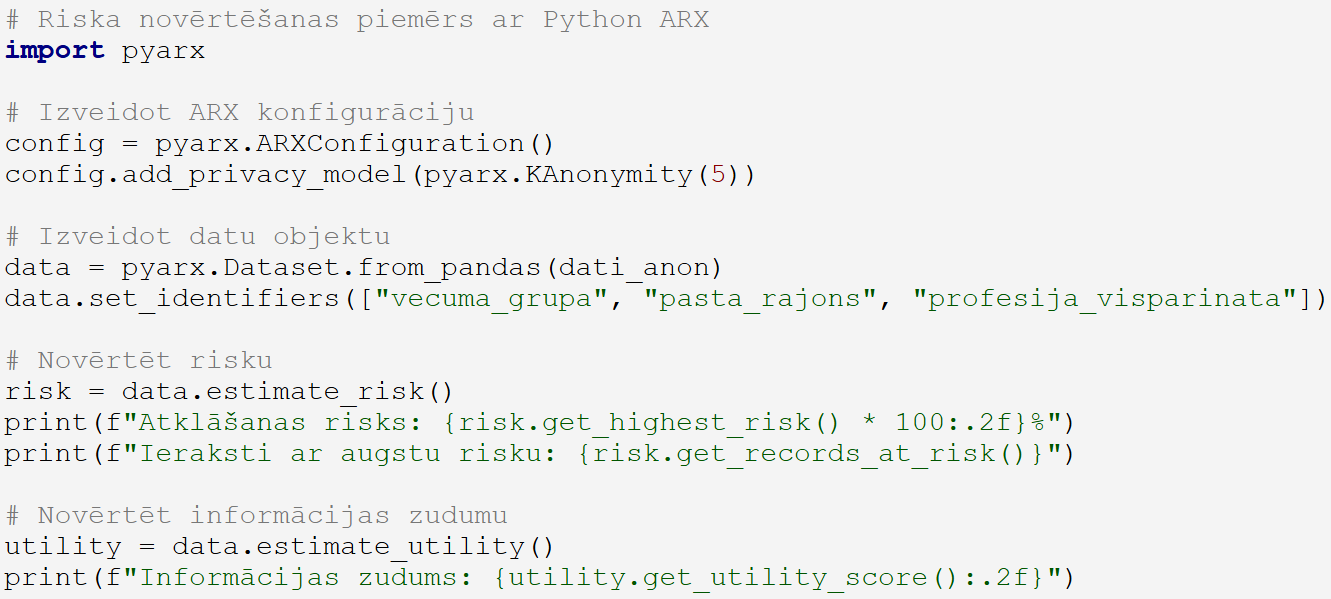
Kompromiss starp privātumu un lietderību
Anonimizācijas kvalitātes novērtēšanā ir svarīgi atrast līdzsvaru starp privātuma aizsardzību un datu lietderību. Augstāka privātuma aizsardzība parasti nozīmē lielāku informācijas zudumu un potenciāli zemāku datu lietderību. Šo kompromisu var vizualizēt, izmantojot privātuma-lietderības diagrammas, kas parāda dažādu anonimizācijas metožu un parametru ietekmi.
Optimālas anonimizācijas stratēģijas izvēle ir atkarīga no konkrētā pētījuma konteksta, datu jutīguma un paredzētā izmantošanas mērķa. Pētniekiem jānosaka pieņemamais atklāšanas riska līmenis, ņemot vērā potenciālo kaitējumu indivīdiem reidentifikācijas gadījumā, un jāizvēlas anonimizācijas metodes, kas nodrošina pietiekamu privātuma aizsardzību, vienlaikus saglabājot nepieciešamo datu analītisko vērtību.
Regulāra anonimizācijas kvalitātes novērtēšana ir būtiska, jo jauni dati, metodes vai ārējā informācija var mainīt atklāšanas risku laika gaitā. Tāpēc ieteicams periodiski pārskatīt un atjaunināt anonimizācijas stratēģijas, lai nodrošinātu ilgtermiņa privātuma aizsardzību.
Efektīva datu anonimizācija prasa ne tikai tehnisko metožu pielietošanu, bet arī sistemātisku pieeju un rūpīgu dokumentāciju. Šajā sadaļā aplūkotas labās prakses un vadlīnijas, kas palīdzēs nodrošināt kvalitatīvu un uzticamu datu anonimizāciju pētniecības projektos.
Anonimizācijas plānošana un sagatavošana:
anonimizācijas mērķu definēšana: pirms anonimizācijas procesa uzsākšanas ir svarīgi skaidri definēt, kāpēc dati tiek anonimizēti un kā tie tiks izmantoti pēc anonimizācijas. Šī izpratne palīdzēs izvēlēties piemērotākās metodes un novērtēt nepieciešamo anonimizācijas līmeni. Piemēram, ja dati tiks publicēti atvērtā piekļuvē, būs nepieciešams augstāks anonimizācijas līmenis nekā tad, ja tie tiks kopīgoti tikai ar uzticamiem pētniekiem kontrolētā vidē;
datu inventarizācija: pirms anonimizācijas veikšanas ir jāveic rūpīga datu inventarizācija, identificējot visus tiešos identifikatorus, kvazi-identifikatorus un sensitīvos atribūtus. Šajā posmā ir svarīgi iesaistīt nozares ekspertus, kas var palīdzēt identificēt netiešos identifikatorus, kas var nebūt acīmredzami. Piemēram, medicīnas pētījumos retas slimības vai specifiskas ārstēšanas metodes var kalpot kā netiešie identifikatori;
riska novērtēšana: pirms anonimizācijas metožu izvēles ir jāveic sākotnējais re-identifikācijas riska novērtējums, ņemot vērā datu kontekstu, potenciālos “uzbrucējus” un pieejamo ārējo informāciju. Šis novērtējums palīdzēs noteikt, kāds anonimizācijas līmenis ir nepieciešams un kuras metodes būtu vispiemērotākās. Piemēram, ja pētījums tiek veikts mazā kopienā vai specifiskā profesionālā grupā, reidentifikācijas risks var būt augstāks;
juridisko prasību apzināšana: pirms anonimizācijas ir jāiepazīstas ar attiecīgajiem datu aizsardzības likumiem un noteikumiem (piemēram, VDAR Eiropas Savienībā) un jānodrošina, ka anonimizācijas process atbilst šīm prasībām. Tas var ietvert konsultācijas ar datu aizsardzības speciālistiem vai juridiskajiem ekspertiem;
ētikas apsvērumu iekļaušana: anonimizācijas plānošanā ir jāņem vērā ne tikai juridiskie, bet arī ētiskie aspekti, t.sk. potenciālais kaitējums indivīdiem reidentifikācijas gadījumā un datu subjektu tiesības un intereses. Īpaši svarīgi tas ir sensitīvu datu, piemēram, veselības vai finanšu informācijas gadījumā.
Anonimizācijas procesa dokumentēšana:
metodoloģijas dokumentēšana: detalizēti dokumentējiet visas izmantotās anonimizācijas metodes, to parametrus un pamatojumu šo metožu izvēlei. Šī dokumentācija ir būtiska gan pētniecības pārredzamībai, gan lai nodrošinātu, ka citi pētnieki var izprast un novērtēt anonimizācijas kvalitāti. Piemēram, ja tiek izmantota k-anonimitāte, dokumentējiet izvēlēto k vērtību un tās izvēles pamatojumu;
koda un skriptu saglabāšana: saglabājiet visus kodus, skriptus vai rīkus, kas izmantoti anonimizācijas procesā, kopā ar komentāriem un instrukcijām par to lietošanu. Tas palīdzēs nodrošināt anonimizācijas procesa reproducējamību un ļaus to pārskatīt vai modificēt nepieciešamības gadījumā;
izmaiņu žurnāla vešana: dokumentējiet visas izmaiņas, kas veiktas datu kopā anonimizācijas procesā, t.sk. noņemtos vai modificētos atribūtus un to sākotnējās vērtības (vispārīgā formā). Šī informācija var būt noderīga, novērtējot anonimizācijas ietekmi uz datu analīzi;
riska novērtējuma rezultātu dokumentēšana: saglabājiet visu veikto riska novērtējumu rezultātus, tostarp identificētos riskus, to novērtējumu un veiktos pasākumus risku mazināšanai. Šī dokumentācija ir būtiska, lai pamatotu anonimizācijas procesa pietiekamību un atbilstību;
datu lietderības novērtējuma dokumentēšana: dokumentējiet, kā anonimizācija ir ietekmējusi datu lietderību, tostarp izmaiņas galvenajos statistiskajos rādītājos un datu sadalījumos. Šī informācija palīdzēs citiem pētniekiem izprast anonimizācijas ietekmi uz datu analīzes rezultātiem.
Anonimizēto datu pārvaldība:
versiju kontrole: ieviešot versiju kontroli anonimizētajiem datiem, nodrošiniet, ka var izsekot dažādām anonimizācijas versijām un izmaiņām laika gaitā. Tas ir īpaši svarīgi, ja anonimizācijas process tiek modificēts vai uzlabots, pamatojoties uz jauniem riskiem vai metodēm;
piekļuves kontrole: ieviešot atbilstošus piekļuves kontroles mehānismus anonimizētajiem datiem, nodrošiniet, ka tiem var piekļūt tikai autorizēti lietotāji un ka dati tiek izmantoti tikai paredzētajiem mērķiem. Pat ja dati ir anonimizēti, to piekļuves kontrole ir laba prakse;
datu lietošanas nosacījumu definēšana: skaidri definējiet, kā anonimizētos datus drīkst izmantot, kopīgot vai publicēt, un nodrošiniet, ka šie nosacījumi tiek paziņoti visiem datu lietotājiem. Tas var ietvert aizliegumu mēģināt reidentificēt indivīdus vai kombinēt datus ar citiem avotiem, kas varētu apdraudēt anonimitāti;
regulāra risku pārskatīšana: periodiski pārskatiet anonimizācijas efektivitāti, ņemot vērā jaunus datus, metodes vai ārējo informāciju, kas varētu palielināt reidentifikācijas risku. Anonimizācija nav vienreizējs process, bet gan nepārtraukta darbība, kas jāpielāgo mainīgajai videi;
incidentu pārvaldības plāns: izstrādājiet plānu rīcībai gadījumā, ja tiek atklāta reidentifikācijas iespēja vai notiek datu aizsardzības incidents. Šis plāns var ietvert procedūras incidenta novērtēšanai, iesaistīto pušu informēšanai un korektīvo darbību veikšanai.
Komunikācija un apmācība:
skaidra komunikācija ar datu subjektiem: nodrošiniet, ka datu subjekti (pētījuma dalībnieki) tiek pienācīgi informēti par to, kā viņu dati tiks anonimizēti un izmantoti. Tas ir būtisks aspekts informētās piekrišanas procesā un palīdz veidot uzticību starp pētniekiem un dalībniekiem;
pētnieku apmācība: nodrošiniet, ka visi pētnieki, kas strādā ar sensitīviem datiem, ir apmācīti par datu anonimizācijas principiem, metodēm un labajām praksēm. Šī apmācība var ietvert praktiskus vingrinājumus un gadījumu izpētes, lai attīstītu praktiskas prasmes;
sadarbība ar datu aizsardzības speciālistiem: veidojiet sadarbību ar datu aizsardzības speciālistiem vai ētikas komitejām, lai nodrošinātu, ka anonimizācijas process atbilst visām juridiskajām un ētiskajām prasībām. Šī sadarbība var sniegt vērtīgas zināšanas un perspektīvas, kas var uzlabot anonimizācijas kvalitāti;
atvērtība par ierobežojumiem: esiet atklāti par anonimizācijas ierobežojumiem un atlikušajiem riskiem, kad komunicējat par anonimizētajiem datiem. Šī pārredzamība palīdz veidot reālistiskas gaidas un veicina uzticību pētniecības procesam;
zināšanu apmaiņa: dalieties ar savām zināšanām un pieredzi datu anonimizācijā ar plašāku pētniecības kopienu, piedaloties konferencēs, publicējot rakstus vai veidojot atvērtā koda rīkus. Šī zināšanu apmaiņa veicina labāku prakšu attīstību un uzlabošanu visā nozarē.
Ievērojot šīs labās prakses un dokumentācijas vadlīnijas, pētnieki var nodrošināt, ka viņu datu anonimizācijas process ir sistemātisks, pārredzams un efektīvs, vienlaikus ievērojot juridiskās un ētiskās prasības. Tas ne tikai aizsargā pētījuma dalībnieku privātumu, bet arī veicina uzticību pētniecības procesam un rezultātiem.
Abu Attieh H., Müller A., Wirth F. N., Prasser F. (2025). Pseudonymization tools for medical research: a systematic review. BMC Medical Informatics and Decision Making, 25 (1), pp. 1–10. DOI: 10.1186/s12911-025-02958-0
Carvalho T., Moniz N., Faria P., Antunes L. (2023). Survey on Privacy-Preserving Techniques for Microdata Publication. ACM Computing Surveys, 55 (14 S), pp. 1–42. DOI: 10.1145/3588765
Sepas A., Bangash A. H., Alraoui O., El Emam K., El-Hussuna A. (2022). Algorithms to anonymize structured medical and healthcare data: A systematic review. Frontiers in Bioinformatics, 2, pp. 1–11. DOI: 10.3389/fbinf.2022.984807
Stinar F., Xiong Z., Bosch N. (2024). An Approach to Improve k-Anonymization Practices in Educational Data Mining. Journal of Educational Data Mining, 16 (1), pp. 61–83. DOI: 10.5281/zenodo.11056083
Tomás J., Rasteiro D., Bernardino J. (2022). Data Anonymization: An Experimental Evaluation Using Open-Source Tools. Future Internet, 14 (6), pp. 1–20. DOI: 10.3390/fi14060167