
Datu apstrāde
 Datu apstrāde pētniecībā ir process, kas pārvērš neapstrādātus datus lietojamā formā. Tā ietver iegūšanu, tīrīšanu, integrāciju, transformāciju, samazināšanu un sagatavošanu analīzei, kas nodrošina rezultātu precizitāti un uzticamību. Neatkarīgi no tā, vai pētījumā tiek izmantoti kvantitatīvi vai kvalitatīvi dati, datu apstrāde ir pamats, uz kura balstās pētniecība.
Datu apstrāde pētniecībā ir process, kas pārvērš neapstrādātus datus lietojamā formā. Tā ietver iegūšanu, tīrīšanu, integrāciju, transformāciju, samazināšanu un sagatavošanu analīzei, kas nodrošina rezultātu precizitāti un uzticamību. Neatkarīgi no tā, vai pētījumā tiek izmantoti kvantitatīvi vai kvalitatīvi dati, datu apstrāde ir pamats, uz kura balstās pētniecība.
Pētniecības datu apstrādes etapi
Pētniecības datu apstrādi var iedalīt trīs saistītos etapos:
datu iegūšana - uzdevumam nepieciešamo datu savākšana un fiksēšana noteiktā apjomā, kvalitātē un formātā;
datu pirmapstrāde – datu kvalitātes pārbaude, kļūdainu vai nepilnīgu vērtību identificēšana un korekcija, trūkstošo datu apstrāde, trokšņu mazināšana. Atkarībā no pētījuma vajadzībām šajā posmā var veikt arī normalizēšanu, lai nodrošinātu datu salīdzināmību;
datu analīze – apstrādāto datu izpēte ar statistiskām, matemātiskām un modelēšanas metodēm, lai identificētu sakarības un tendences, un pamatotu zinātniskus secinājumus;
datu vizualizācija – rezultātu attēlošana strukturētā un vizuāli uztveramā formā (piemēram, diagrammās, grafikos, kartēs vai interaktīvās vizualizācijās), kas atvieglo interpretāciju un komunikāciju.
Pētniecības datu apstrāde ir dinamisks, atkārtots process – dati tiek regulāri pārskatīti, papildināti un precizēti visa pētījuma laikā. Ikvienā etapā īpaši svarīgi ievērot drošības, konfidencialitātes un privātuma principus.
Šajā sadaļā ir īsi apkopoti galvenie datu apstrādes etapi, sākot no datu iegūšanas līdz to analīzei, kā arī apskatīti biežāk lietotie rīki.
Datu pirmapstrādes nozīme
Datu pirmapstrāde ir svarīga, jo tā palīdz nodrošināt informācijas precizitāti, konsekvenci un sagatavo tos tālākai analīzei. Ja dati netiek pienācīgi sagatavoti, pat kvalitatīvi apkopotas datu kopas var radīt kļūdainus secinājumus.
Datu pirmapstrādes galvenie posmi
Datu apstrādes process parasti ietver šādus posmus:
datu iegūšana – datu vākšana no dažādiem avotiem (aptaujas, sensori, datubāzes u.c.);
datu tīrīšana – kļūdu, trūkstošu vērtību un dublikātu identificēšana un novēršana;
datu integrācija – datu apvienošana no dažādiem avotiem vienotā struktūrā;
datu transformācija – datu pārveidošana piemērotā formātā un mērogā;
datu samazināšana – datu apjoma samazināšana, saglabājot būtisko informāciju.
Posmu izvēle un detalizācija atkarīga no pētījuma mērķa, datiem un analīzes metodēm.
Datu iegūšana ir pirmais posms pirmapstrādes procesā, kas lielā mērā nosaka turpmākā darba kvalitāti. Tās mērķis ir sistemātiski savākt nepieciešamo informāciju, lai atbildētu uz pētījuma jautājumiem vai pārbaudītu hipotēzes. Dati var tikt iegūti tieši (piemēram, ar aptaujām, eksperimentiem, intervijām, novērojumiem vai mērījumiem) vai netieši, izmantojot jau esošus avotus (piemēram, statistikas datubāzes, uzņēmumu reģistrus, sensoru datus, arhīvus vai datu repozitorijus u.c.).
Datu iegūšanas principi:
precizitāte – dati jāievāc tā, lai tie atspoguļotu reālo situāciju un nebūtu kļūdaini;
sistēmisks process – datu iegūšana jāplāno un jāveic konsekventi, ievērojot vienotu metodiku;
objektivitāte – jāizvairās no subjektīviem spriedumiem un ietekmes uz respondentu vai datu avotu;
ētika un drošība – jāievēro konfidencialitāte, datu aizsardzības noteikumi un personas datu apstrādes prasības (piemēram, VDAR/GDPR);
atbilstoša forma – dati jāsavāc tādā struktūrā un formātā, kas ļauj tos ērti apstrādāt un analizēt (piemēram, tabulās, CSV failos vai datubāzēs).
Datu iegūšanas metodes
Datu iegūšanas process var būt gan automatizēts (piemēram, sensoru tīkli vai tiešsaistes datu ieguve ar programmatūras palīdzību), gan manuāls (piemēram, interviju vai anketu aizpildīšana). Izvēle starp šīm metodēm atkarīga no pētījuma mērķa, resursiem, datu veida un to pieejamības.
Datu veidi
Datus pēc to veida parasti iedala divās grupās – kvalitatīvi un kvantitatīvi dati. Kvalitatīvie dati raksturo parādību saturiski un kontekstuāli, atspoguļojot cilvēku pieredzi, viedokļus un nozīmes. Tie parasti ir teksti, intervijas, novērojumi vai vizuāli materiāli, kas palīdz izprast pētāmās problēmas nianses. Kvantitatīvie dati savukārt ir skaitliska informācija, kas ļauj izmērīt, salīdzināt un analizēt parādības, izmantojot statistiskās metodes. Tie sniedz iespēju noteikt tendences un likumsakarības lielākos datu apjomos.
Kvalitatīvajā pētniecībā būtiski nodrošināt, lai dati būtu dziļi, kontekstuāli bagāti un atspoguļotu pētāmās parādības daudzslāņainību, savukārt kvantitatīvajā pētniecībā – lai tie būtu precīzi, uzticami un savstarpēji salīdzināmi. Abos gadījumos datu iegūšanas procesa kvalitāte ir tā, kas nosaka tālākās datu izmantošanas iespējas.
Datu tīrīšana ir apstrādes posms, kas nodrošina, lai datu nepilnības un kļūdas neietekmētu analīzes rezultātus un lēmumu pieņemšanu. Tās mērķis ir padarīt datus precīzus, pilnīgus un konsekventus.
Galvenie datu tīrīšanas soļi:
trūkstošo vērtību apstrāde (piemēram, aizstāšana ar vidējo, mediānu vai, balstoties uz līdzīgu gadījumu analīzi);
formātu un mērvienību neatbilstību novēršana (piemēram, datumu formāti, mērījumu vienības);
kļūdu un dublikātu noņemšana vai korekcija;
netipisku mērījumu (outliers) atpazīšana un apstrāde;
datu loģiskās pareizības pārbaude (piemēram, cilvēka vecums nedrīkst būt negatīvs).
Daži no populārākajiem rīkiem datu tīrīšanai ir OpenRefine, Data Wrangler, Python (pandas, NumPy) un R.
Pētījumā iegūtie dati bieži nāk no dažādiem avotiem – atšķirīgām aptaujām, sistēmām, mērījumu ierīcēm vai datubāzēm. Lai ar tiem varētu strādāt, nepieciešama integrācija – datu apvienošana kopīgā formātā un struktūrā.
Integrācijas uzdevumi ir:
apvienot vairākus datu avotus vienotā datu kopā;
saskaņot mainīgos (piemēram, nodrošināt, ka datumi, mērvienības vai kategorijas visur tiek apzīmētas vienādi);
novērst neatbilstības, kas rodas, ja dažādi avoti satur pretrunīgu informāciju;
sagatavot pamatu tālākai datu apstrādei un analīzei.
Integrācijas piemērs
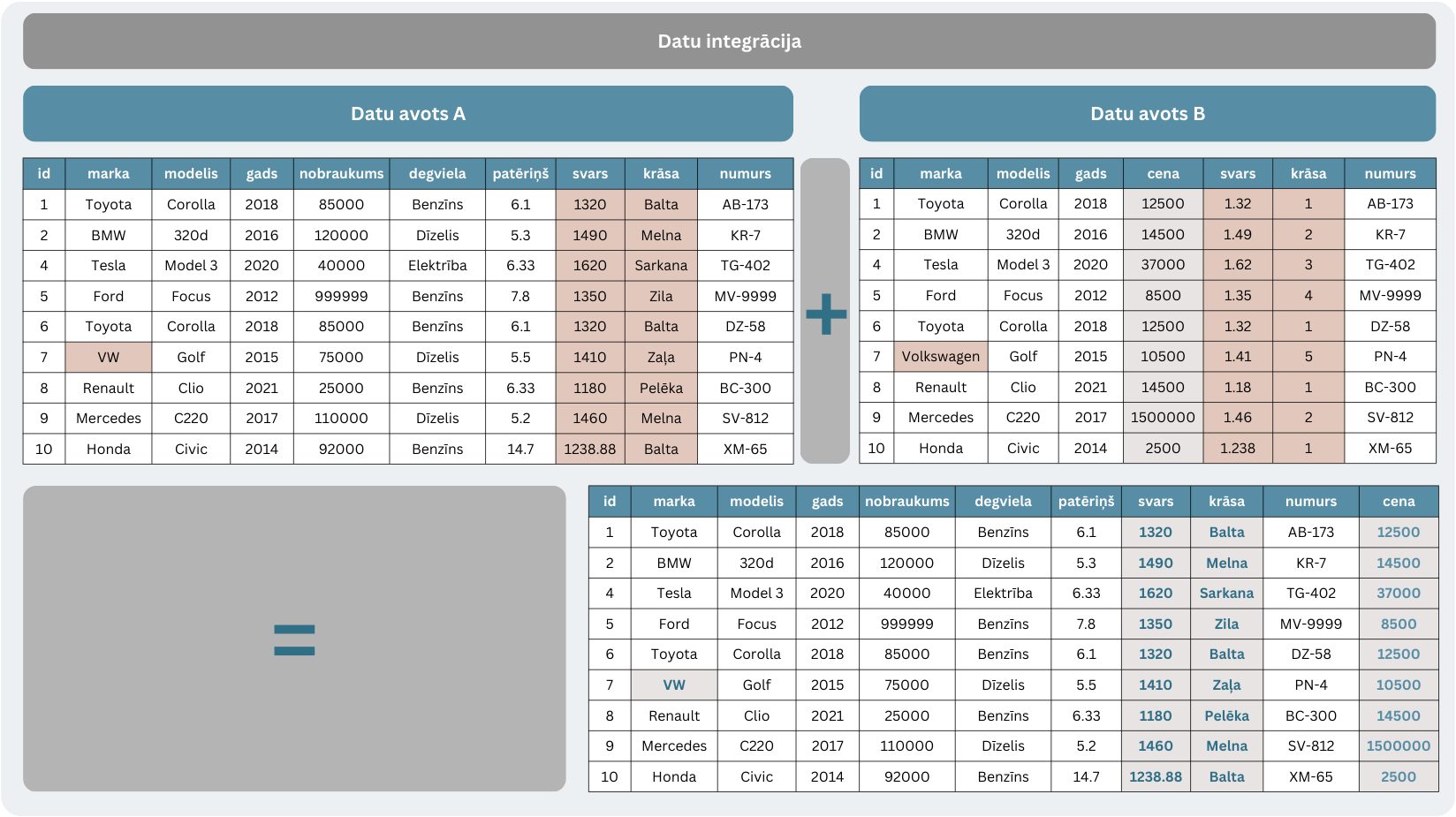
Integrācijas procesā var izmantot dažādus rīkus, piemēram, SQL datubāzes, Excel, Python (pandas merge funkciju) vai lielo datu platformas, piemēram, Apache Spark. Arī rīki, kas pieminēti datu tīrīšanas sadaļā, var tikt pielietoti šiem uzdevumiem. Labi integrēti dati nozīmē, ka pētnieks var redzēt pilnīgu un konsekventu ainu par pētāmo problēmu, nevis fragmentētas datu kopas.
Transformācijas mērķis ir sagatavot datus analīzei, piemēram, normalizējot, standartizējot vai vienādojot mērvienības. Datu pārveide ietver arī kategoriju kodēšanu, grupēšanu, jaunu mainīgo izveidi un laika datu apstrādi.
Transformācijas piemērs (attēlā redzama datu diapazona vienādošana, kas ir nepieciešama pirms MI algoritmu apmācības un citos gadījumos)
Veiksmīga datu transformācija nereti prasa arī datu pielāgošanu specifiskām analīzes vajadzībām, piemēram, izveidojot jaunas kategorijas vai mainīgos, kas ļauj precīzāk interpretēt pētījuma rezultātus. Šajā posmā var izmantot gan manuālas metodes, gan automatizētas funkcijas, kas palīdz efektīvi apstrādāt dažādu tipu informāciju.
Datu samazināšanas uzdevums ir reducēt datu apjomu, nezaudējot būtisku informāciju. To izmanto, lai paātrinātu apstrādi un uzlabotu analīzes efektivitāti. Datu samazināšanas procesa grūtākais uzdevums ir izlemt, kuri dati ir būtiski un saglabājami, un bez kuriem ir iespējams iztikt.
To panāk, izmantojot tādas metodes, kā galveno komponentu analīze (PCA), mainīgo atlase (feature selection), datu apvienošana vai grupēšana. Šis solis ir īpaši svarīgs “lielo datu” (big data) gadījumos, kad datu daudzums ir ievērojams un to apstrāde var būt laikietilpīga.
Analīzes process un metodes
Zinātnisko datu analīze ir process, kurā no iepriekš apstrādātiem un sakārtotiem datiem iegūst jaunu izpratni par pētāmo parādību. Tā ietver gan aprakstošo statistiku (piemēram, vidējās vērtības, mediānas un standartnovirzes aprēķinus), gan sarežģītākas metodes, piemēram, regresijas modeļus, dispersijas analīzi vai laika rindu prognozēšanu.
Analīzes mērķi un pieejas
Analīze palīdz atklāt likumsakarības, pārbaudīt hipotēzes un pamatot secinājumus ar statistiskiem rādītājiem. Bieži izmanto šādas pieejas:
aprakstošā analīze – datu kopsavilkumu veidošana un tendenču un izkliedes rādītāju aprēķināšana;
izpētošā analīze – datu struktūras un sakarību izpēte, anomāliju identificēšana;
secinošā analīze – hipotēžu pārbaude un statistisko secinājumu izdarīšana;
prognozējošā analīze – modeļu veidošana nākotnes tendenču paredzēšanai;
preskriptīvā analīze – optimālu risinājumu identificēšana, balstoties uz analīzes rezultātiem.
Analīzes rīki un interpretācija
Analīzē bieži izmanto programmēšanas valodas un programmatūru, kas paredzēta lielu un sarežģītu datu kopu apstrādei, piemēram, Python (pandas, NumPy, scikit-learn), R, kā arī statistikas pakotnes SPSS vai SAS. Atsevišķās nozarēs tiek izmantoti arī specializēti rīki, piemēram, MATLAB inženiertehniskiem aprēķiniem vai Stata ekonomikas un sociālo zinātņu analīzei.
Statistiskās analīzes rīki: SPSS, R, Stata, Microsoft Excel.
Datu tīrīšana un pārveidošana: OpenRefine, Data Wrangler, Python (pandas, NumPy), R.
Programmēšanas un automatizācijas rīki: Python (pandas, NumPy, scikit-learn), R.
Lielo datu apstrādes risinājumi: Apache Spark, Hadoop.
Datu vizualizācijas rīki: Tableau, Power BI, Matplotlib.
University of Illionois (2023). Data Cleaning for the Non-Data Scientist. [tiešsaiste] [skatīts 03/03/2026]. Pieejams: https://guides.library.illinois.edu/datacleaning/tools
Stony Brook University (2026). Data Cleaning and Wrangling Guide. [tiešsaiste] [skatīts 03/03/2026]. Pieejams: https://guides.library.stonybrook.edu/data-cleaning-and-wrangling/cleaning
O'Toole T., Cernat A., Tzavidis N., Shlomo N., Sakshaug J. (2025). Survey Practice Guide 1: Data Integration. [tiešsaiste] [skatīts 03/03/2026]. Pieejams: https://surveyfutures.net/wp-content/uploads/2025/05/survey-practice-guide-1-data-integration.pdf
UMBC (2026). Data Integration, Analysis, and Visualization. [tiešsaiste] [skatīts 03/03/2026]. Pieejams: https://lib.guides.umbc.edu/c.php?g=1078066&p=8197208